Fundamentos de muestreo y manejo de datos
Versión PDF
II-1120 Estadística para Ingeniería Industrial I
II-1123 Estadística para Ingeniería Industrial II (transición)
26 de febrero de 2026
Contexto
Estas lecciones tienen como propósito desarrollar métodos de muestreo que proporcionen con el menor costo posible, estimaciones con la suficiente exactitud para los propósitos que se diseñen.

Muestreo
El procedimiento mediante el cual obtenemos una o más muestras recibe el nombre de muestreo.
Para Montgomery, es:
El objetivo de la inferencia estadística es extraer conclusiones o tomar decisiones acerca de una población con base en una muestra seleccionada de dicha población.
Existen, al menos, dos tipos de muestreo:
- Probabilístico
- No probabilístico
Importante
La validez de las conclusiones que se extraen o de las decisiones que se toman dependen de la forma en la que se recolectan y analizan los datos.
La estadística es una herramienta poderosa, pero su verdadero valor se obtiene cuando se aplica de manera adecuada y se interpreta dentro de un contexto específico.
El nivel de medición y el tipo de variable rigen los cálculos que se llevan a cabo con el fin de resumir y presentar los datos. Es decir, que no todos los tipos de datos se analizan igual.
¿Cuándo muestrear?
Cuando la población sea infinita: o tan grande que el censo exceda de las posibilidades del investigador.
Cuando la población sea suficientemente uniforme: para que cualquier muestra dé una buena representación de esta y carezca de sentido examinar la población completa.


Cuando el proceso de medida o investigación de las características de cada elemento sea destructivo.
Ejemplo de sesgo
El sesgo del superviviente es uno muy famoso.
- Quizá algún día haya visto esta imagen.
Es una falacia lógica que consiste en centrarse en aquellos que han logrado sobrevivir a un proceso, ignorando a aquellos que no lo lograron.
Por ejemplo:
- Todos los emprendedores exitosos abandonaron la universidad, así que dejar la carrera aumenta tus probabilidades de éxito

Etapas
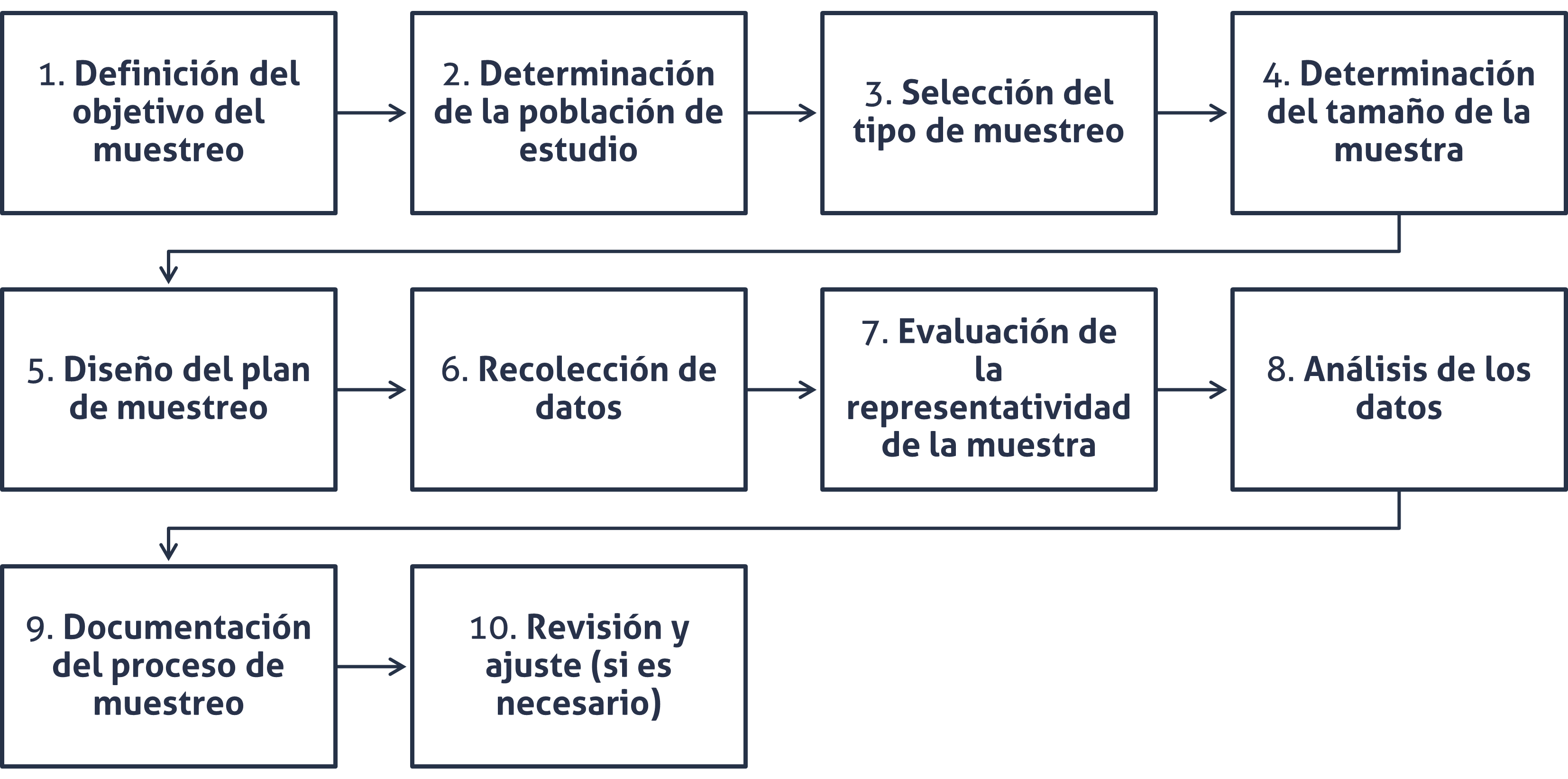
1. Definición del objetivo del muestreo
- El primer paso es definir claramente qué se desea lograr con el muestreo.
- Esto implica identificar el problema de investigación o la pregunta que se desea responder, las hipótesis que se probarán y el uso que se dará a los resultados obtenidos.

Consideraciones importantes
- Determinar las variables clave que se estudiarán (por ejemplo, edad, ingresos, preferencias, dimensiones críticas de una pieza mecánica, peso, porcentaje de condimentación, percepción de calidad, entre otros).
- Especificar si el objetivo es descriptivo (describir características de una población), analítico (encontrar relaciones o diferencias) o predictivo (predecir tendencias o comportamientos futuros).
2. Determinación de la población de estudio
- Definir claramente quiénes son los elementos que componen la población objetivo, es decir, el grupo completo de individuos o unidades que se desea estudiar.

Consideraciones importantes
- Especificar criterios de inclusión y exclusión que definan claramente quién pertenece a la población de estudio.
- Por ejemplo, edad, ubicación geográfica, comportamiento de compra, etc.
- Definir la “unidad de análisis,” que podría ser una persona, una empresa, un producto, etc.
3. Selección del tipo de muestreo
- Decidir qué método de muestreo es el más adecuado para obtener una muestra representativa.
Consideraciones importantes
- Algunas técnicas de muestreo son más económicas que otras, así como algunas son más precisas.
- Lo que se busca es un adecuado balance entre ambas.
5. Diseño del plan de muestreo
- Elaborar un plan detallado que describa cómo se seleccionarán los elementos de la población.

Consideraciones importantes
- Especificar el método de muestreo seleccionado y los procedimientos exactos que se seguirán.
- Definir herramientas y recursos necesarios, como listas de población, software de selección, encuestas, instrumentos de medición, entre otros.
- Incluir instrucciones específicas para los recolectores de datos para evitar sesgos de selección.
6. Recolección de datos
- Implementar el plan de muestreo y recolectar los datos de los elementos seleccionados

Consideraciones importantes
- Seguir los protocolos establecidos para asegurar la consistencia y precisión de los datos. Durante la recolección de datos no se improvisa.
- Utilizar herramientas tecnológicas, como aplicaciones móviles o encuestas en línea, para facilitar la recolección de datos.
- Monitorear continuamente el proceso de recolección para identificar y corregir cualquier desviación del plan.
7. Evaluación de la representatividad
- Verificar si la muestra obtenida es representativa de la población de estudio.
Consideraciones importantes
- Comparar las características clave de la muestra con las de la población para detectar posibles sesgos.
- Utilizar estadísticas descriptivas y gráficas para evaluar la representatividad.
- Ajustar mediante ponderación si se detectan desviaciones significativas
8. Análisis de los datos
- Realizar el análisis estadístico de los datos recolectados para extraer conclusiones válidas.
- La validez depende de qué tan bien se cumplieron los pasos anteriores. Además, los datos se deben analizar en consecuencia del tipo de variable y el nivel de medición.

Consideraciones importantes
- Utilizar técnicas estadísticas apropiadas en función del tipo de datos y de las hipótesis a probar.
- Considerar la aplicación de técnicas de ponderación e imputación para corregir sesgos o datos faltantes.
- Presentar los resultados de manera clara y comprensible (y ética), utilizando cuadros, gráficos y resúmenes estadísticos.
9. Documentación del proceso de muestreo
- Registrar todos los detalles del proceso de muestreo para asegurar la transparencia y la replicabilidad.
- Recuerde que la estadística es un ejercicio ético y moral.

Consideraciones importantes
- Documentar el método de selección de la muestra, el tamaño de la muestra, y cualquier ajuste realizado.
- Guardar registros de todos los datos recolectados, herramientas utilizadas, y problemas encontrados durante el proceso.
- Un ejemplo real: una persona operaria al encontrar una pieza mala, no la registraba, sino que la corregía y anotaba el nuevo valor. Esto impedía a las personas ingenieras detectar un problema en producción.
- Preparar informes que describan el proceso y los resultados del muestreo.
10. Revisión y ajuste (Si es necesario)
- Revisar el plan de muestreo y los resultados para identificar problemas o áreas de mejora.
- El ejercicio de la ingeniería industrial es una búsqueda constante de la excelencia; de la mejora continua.

Consideraciones importantes
- Revisar los resultados para detectar inconsistencias o problemas que sugieran un sesgo de muestreo.
- Realizar ajustes en el plan de muestreo si se identifican problemas, como aumentar el tamaño de la muestra o cambiar el método de muestreo.
- Realizar un segundo muestreo si es necesario para mejorar la representatividad.
Muestreo aleatorio sistemático
Difiere del muestreo aleatorio simple.
Suponga \(N\) unidades de la población que se numeran de 1 a \(N\) en cierto orden, para elegir una muestra de \(n\) unidades se toma una unidad al azar entre las \(k\) primeras y luego se toman las subsecuentes en intervalos de \(k\).
Por ejemplo, si \(k=15\) y la primera unidad que se extrae, al azar, es la número 13, entonces las subsecuentes serán las 28, la 43, 58, etc.
- \[k = \frac{N}{n}\]
La selección de la primera unidad determina toda la muestra.
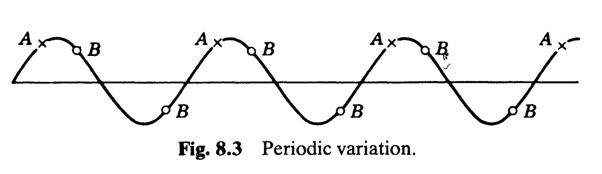
Muestreo aleatorio sistemático
- Si hay una variación periódica (sinusoidal, por ejemplo) la efectividad de este muestreo dependerá del valor de k, donde A sería un valor desfavorable y B uno favorable.
- Aunque una curva perfecta como la del ejemplo no es plausible, esta si es una situación común, como por ejemplo, el comportamiento del flujo de personas o tráfico.
Conglomerados vs Estratos
Estratos:
- En un estudio de ingresos, se decide estratificar por nivel educativo, ya que son variables relacionadas.
- En este caso, se espera que intra-nivel educativo haya un comportamiento homogéneo.
Conglomerados:
- En una encuesta de opinión, se decide entrevistar cada barrio que ha sido seleccionado aleatoriamente en un cantón particular del país.
- En este ejemplo, los subgrupos ya están formados naturalmente y no existe garantía de que sean homogéneos (diferentes niveles socioeconómicos, edades, etc).

Introducción

En una muestra no probabilística, algunos miembros de la población, comparada con otros miembros, tienen una probabilidad mayor (pero desconocida) de ser seleccionados.
Hay 5 principales tipos de muestreo no probabilístico: conveniencia, intencional, cuota, bola de nieve y autoselección.
La principal característica del muestreo probabilístico, que está ausente en el NO probabilístico, es la existencia del marco muestral (lista de elementos en la población, por ejemplo).
- Este tipo de muestreo es muy útil en ausencia del marco muestral.
