| Sabor | Votos |
|---|---|
| Chocolate | 103 |
| Vainilla | 92 |
| Fresa | 72 |
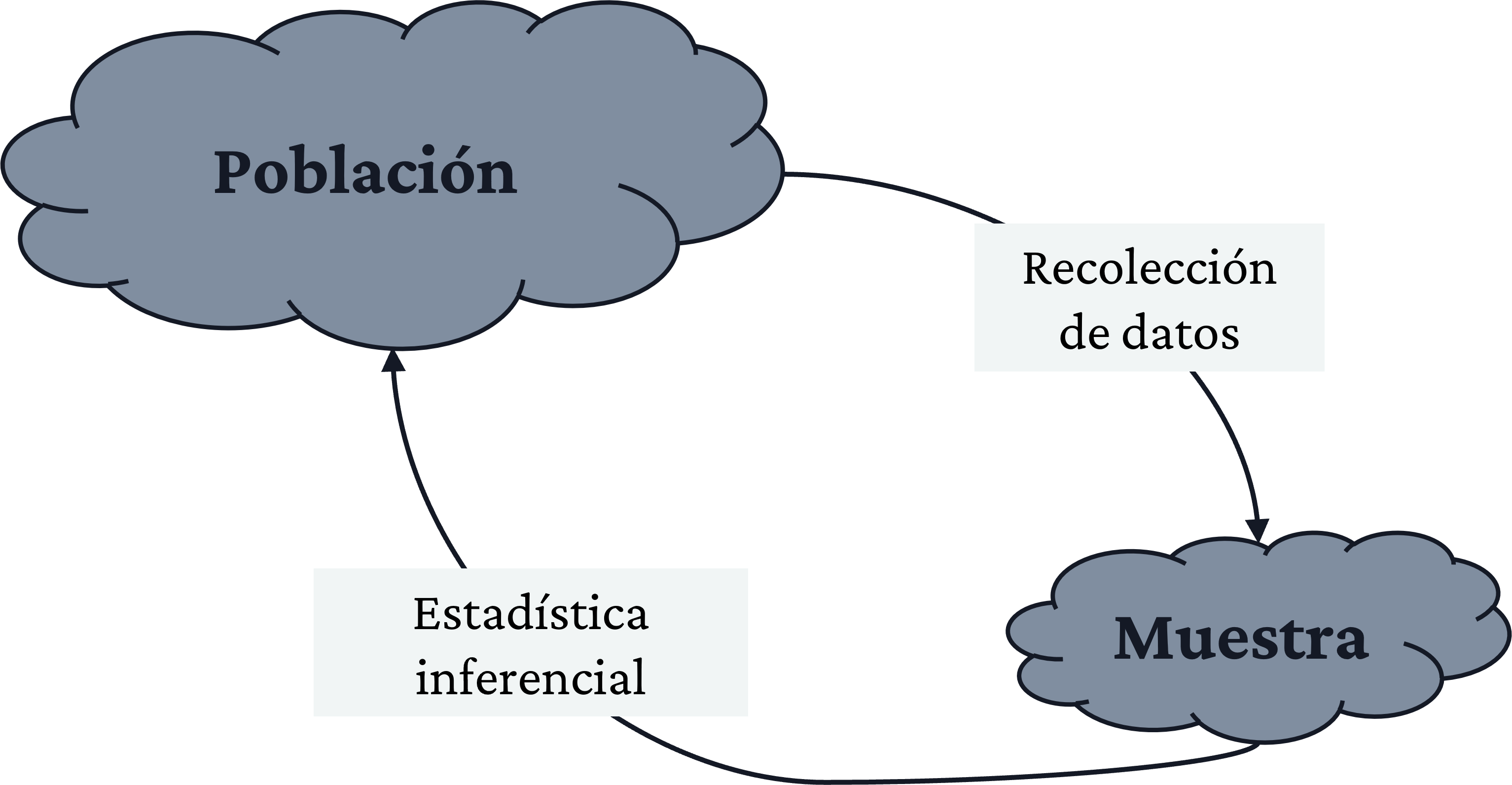
Descripción de datos
Versión PDF
II-1120 Estadística para Ingeniería Industrial I
26 de febrero de 2026
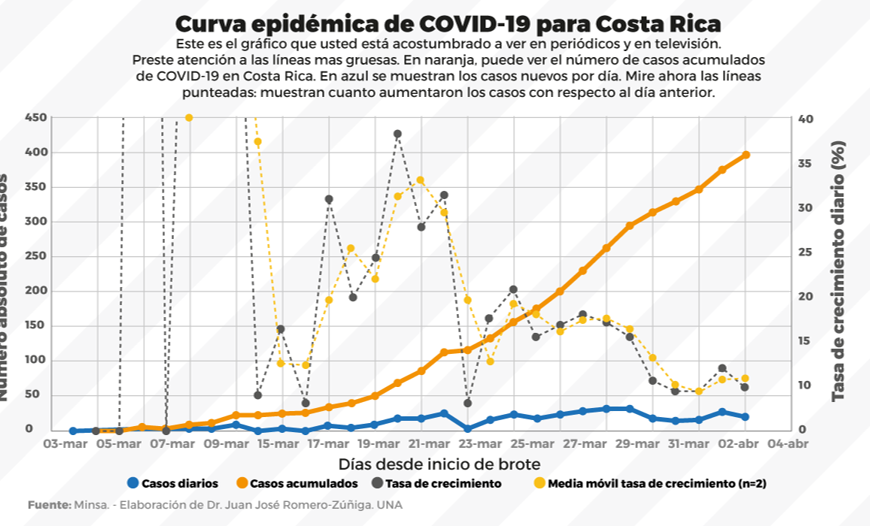
¡Recuerde!
Las variables se pueden clasificar por tipo: Cuantitativa y Cualitativa, así como por niveles de medición: Nominal, Ordinal, Intervalo y Razón.
Éstas determinan cómo se deben recoger y analizar los datos. Es decir, rigen los cálculos que se deben llevar a cabo.
La validez de las conclusiones depende de la fiabilidad de la recolección de datos y de las técnicas de análisis empleadas.
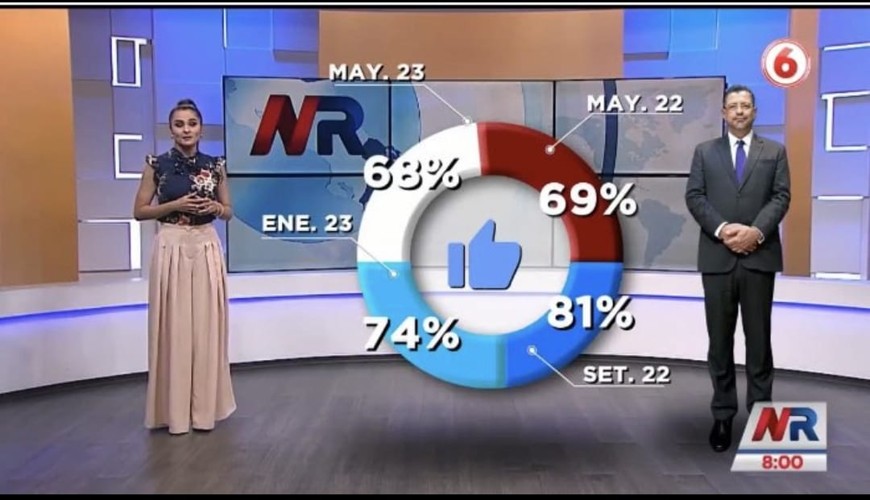
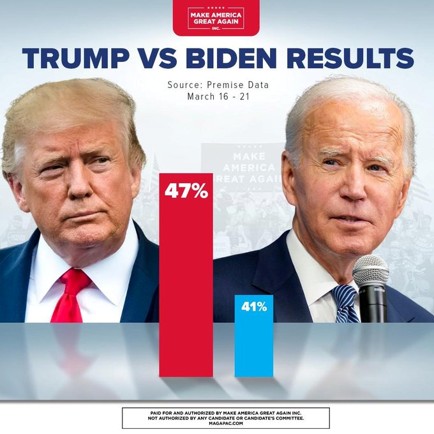
Otro ejemplo
- El ICT informa que la encuesta se realiza durante todo el año y de forma aleatoria. Consiguiendo la respuesta de 5 094 personas.
- ¿Cuál es la población?
- ¿Existe un sesgo evidente en la recolección de los datos?

| Motivo | Porcentaje |
|---|---|
| Vacaciones | 65.10 |
| Visita a familiares | 9.60 |
| Religión/peregrinaciones | 6.40 |
| Educación | 5.90 |
| Salud | 0.60 |
| Compras | 0.30 |
| Incentivo | 0.04 |
| Otros motivos personales | 1.00 |
| Reuniones de negocios | 8.07 |
| Conferencias y congresos | 1.07 |
| Actividades deportivas/culturales | 2.00 |
1. Media o promedio
- Sirve como medida para expresar el centro de una distribución.
- A modo de analogía, la media se puede interpretar como un “centro de gravedad”.
- Esta es la principal desventaja de la media: se ve MUY afectada por la presencia de valores extremos.
- No es una práctica ética eliminar valores extremos sin justificarlo y reportarlo.
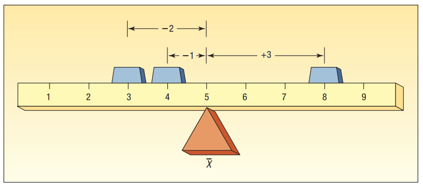
Por ejemplo
- En una muestra, la media de 5 números aproximadamente similares: 4, 3, 5, 4 y 6 es \(\bar{x}=4.4\).
- Esto sería como una regla , “uniforme” en toda la superficie, por lo que el centro de gravedad está en el “centro”.
- La media de 5 números con uno sumamente distinto (valor extremo): 2, 3, 5, 4 y 25 es \(\bar{x}=8.8\).
- Esto sería como un martillo , cargado en un extremo.
- También puede darse el caso de que haya valores extremos en ambas direcciones, comportándose como una mancuerna .
- Por ejemplo: 2, 9, 12, 8, 11, 35 tiene como media \(\bar{x}=12.83\)
Ejemplo

¿Alguna vez se preguntó por el salario en su carrera?
La gran mayoría de estudios responden al salario promedio. Inclusive, muchos de ustedes durante las ferias vocacionales realizan esta pregunta.
¿Eso está bien? La respuesta es ¡no! los salarios casi siempre tienen valores extremos.
Ejemplo
Por ejemplo, en estos valores ordenados:
| valores | 29 | 31 | 35 | 39 | 39 | 40 | 43 | 44 | 44 | 52 |
| Posición | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
La mediana es:
\[\tilde{x}=\frac{1}{2} \cdot (x_{\frac{10}{2}}+x_{\frac{10}{2}+1}) \\ \tilde{x} =\frac{1}{2}\cdot (39 + 40) \\ \tilde{x} =39.5\]

1. Asimetría
Mide el grado de deformación horizontal en un conjunto de datos.
Hay muchos coeficientes de asimetría, todos se interpretan igual, pero se calculan de formas diversas.
Para efectos de este curso vamos a usar el coeficiente de asimetría que se encuentra disponible en Excel.
- \(Sk= \frac{n}{(n-1)(n-2)}\left[\sum_{i=1}^{n}\left(\frac{x_i-\bar{x}}{s}\right)^3\right]\)
- \(Sk<0\): asimetría negativa
- \(Sk=0\): distribución simétrica
- \(Sk>0\): asimetría positiva
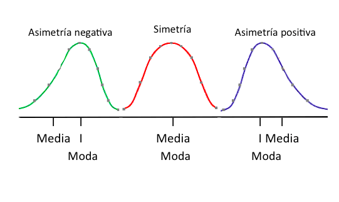
1. Asimetría
- Una distribución puede ser asimétrica y no presentar ningún tipo de sesgo. O viceversa.
- Los términos NO SON intercambiables. Use la terminología correcta.
¿De dónde proviene esto?
- Básicamente, de un “error de traducción”. Para sesgo el término en inglés es bias, mientras que para asimetría es skewness.
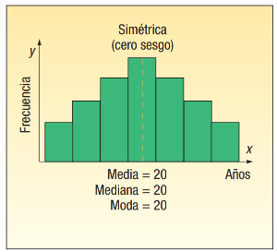
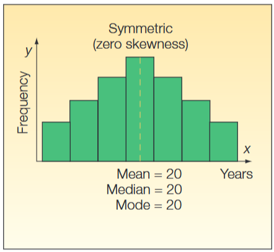
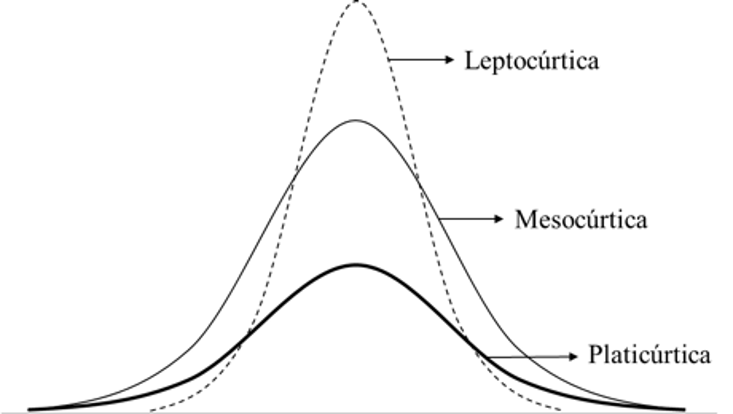
2. Curtosis
Usamos la misma fórmula que MS Excel:
- Esta fórmula mide el exceso de curtosis, es decir, que tan distinta es de una distribución normal (tema que se aborda más adelante en el curso).
\(ku=\left[ \left(\frac{n(n+1)}{(n-1)(n-2)(n-3)}\sum_{i=1}^{n} \left(\frac{x_i-\bar{x}}{s}\right)^4 \right) \right] - \frac{3(n-1)}{(n-2)(n-3)}\)
- \(ku<0\) platicúrtica:
- Donde la curtosis es menor que la de la distribución normal
- \(ku=0\) mesocúrtica:
- Donde la curtosis es igual a la de la distribución normal
- \(ku>0\) leptocúrtica:
- Donde la curtosis es mayor que la de la distribución normal
- \(ku<0\) platicúrtica:
Histogramas
Los histogramas ayudan a dar una estimación de dónde se concentran los valores, cuáles son los extremos y si hay vacíos o valores inusuales.
También son útiles para dar una visión aproximada de la distribución de probabilidad.
Cada barra en un histograma representa la frecuencia tabulada en cada intervalo/bin. El área total del histograma es igual al número de datos, cuando se grafica en frecuencia absoluta.

Valores atípicos
- Son valores dentro del conjunto de datos que difieren de forma “considerable” de los otros valores.
- Importante: los datos atípicos se estudian, pero NO se eliminan sin justificación válida.
- Los gráficos de cajas y bigotes son una herramienta visual para la detección de datos “atípicos”.
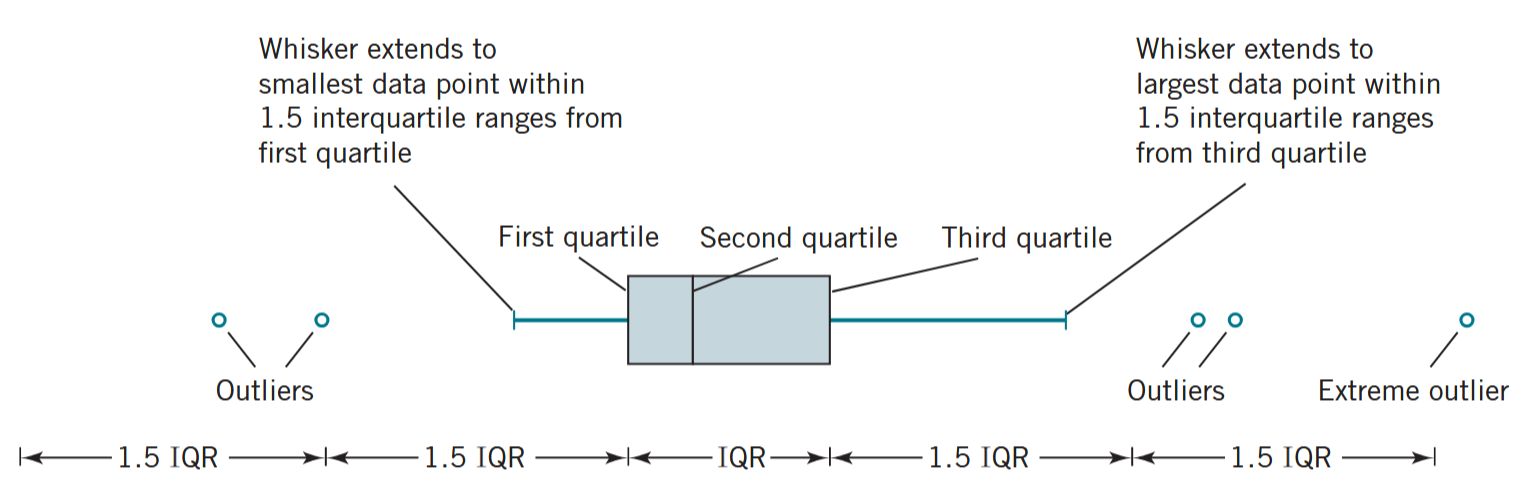
Gráficos de cajas y bigotes

- Extremo superior
- Es el valor extremo superior más pequeño que se encuentre dentro de:
- \(LS=Q_3+1.5\cdot IQR\)
- Es el valor extremo superior más pequeño que se encuentre dentro de:
- Extremo inferior
- Es el valor extremo inferior más pequeño que se encuentre dentro de:
- \(LI=Q_1-1.5\cdot IQR\)
- Es el valor extremo inferior más pequeño que se encuentre dentro de:
- Cualquier valor fuera de LI y LS es considerado “atípico” y debe estudiarse
Dos variables cuantitativas
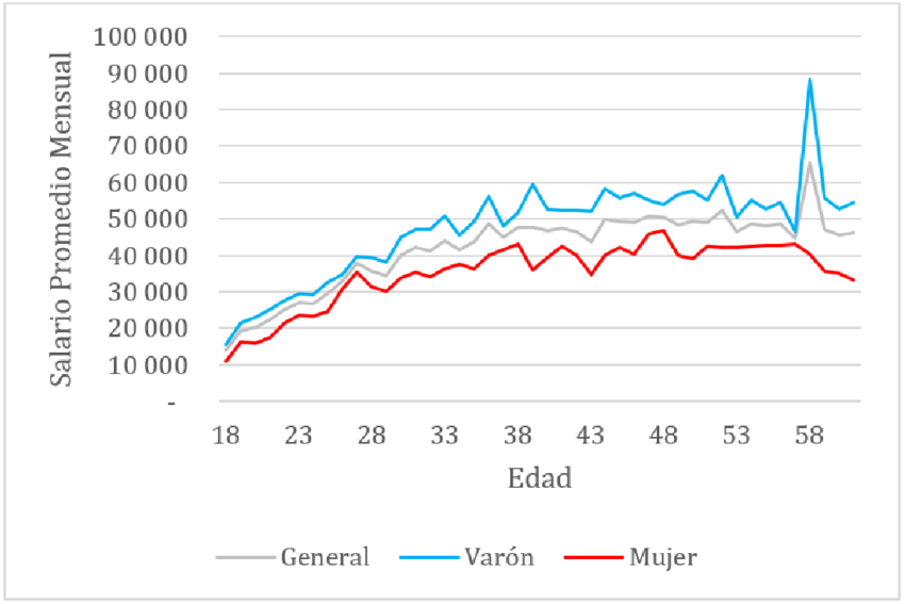
En el gráfico de la izquierda puede encontrar la relación que existe entre el salario promedio mensual y la edad de las personas, clasificadas por género y en general.